Golang并发浅析
本文最后更新于:2022年2月8日 晚上
前言:最近在看学习go channel相关的设计,看了许多博文,感觉知识点还是比较零散,同时极大的感受到,输入的知识点是输出的基础,输入的知识点是低质量的,输出也只能是管中窥豹,所以还是要看官方文档和视频,学习在于输出而不在入呀,遂记录一下学习笔记和心得~
Golang 并发浅析
Channel
Why Channel
在Golang诞生之前,各编程语言都使用多线程进行编程,像笔者之前使用的Java,多线程操作比较复杂、混乱、难以管理,以至于笔者在开发过程中几乎不用多线程操作。
Golang是Google为了解决高并发搜索而设计的,它们想使用简单的方式,高效解决并发问题。
Concurrency is the key to designing high performance network services. Go’s concurrency primitives (goroutines and channels) provide a simple and efficient means of expressing concurrent execution. In this talk we see how tricky concurrency problems can be solved gracefully with simple Go code.
在go开发中有一句至理名言,不要用共享内存来通信,相反,要用通信来共享内存。go语言中的协程goroutine之间的通信就是通过channel来实现的
Do not communicate by sharing memory; instead, share memory by communicating.
也就是说channel是实现不同goroutine之间通信的方式
Channel的设计
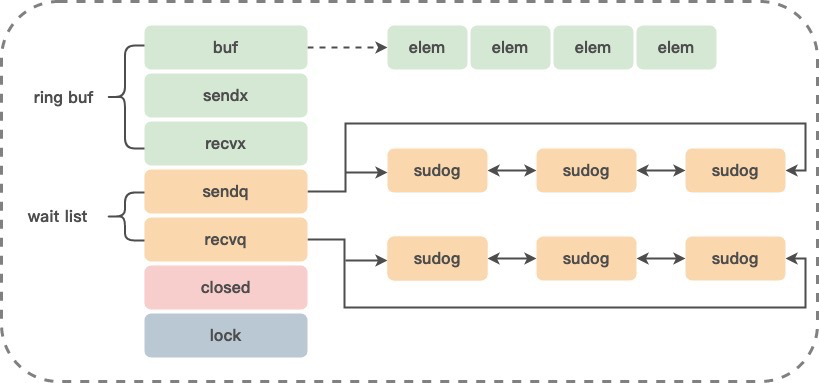
Channel的底层是由runtime.hchan定义的,本质上就是一个有锁的队列,数据经过channel在两个goroutine之间流动:
1 | |
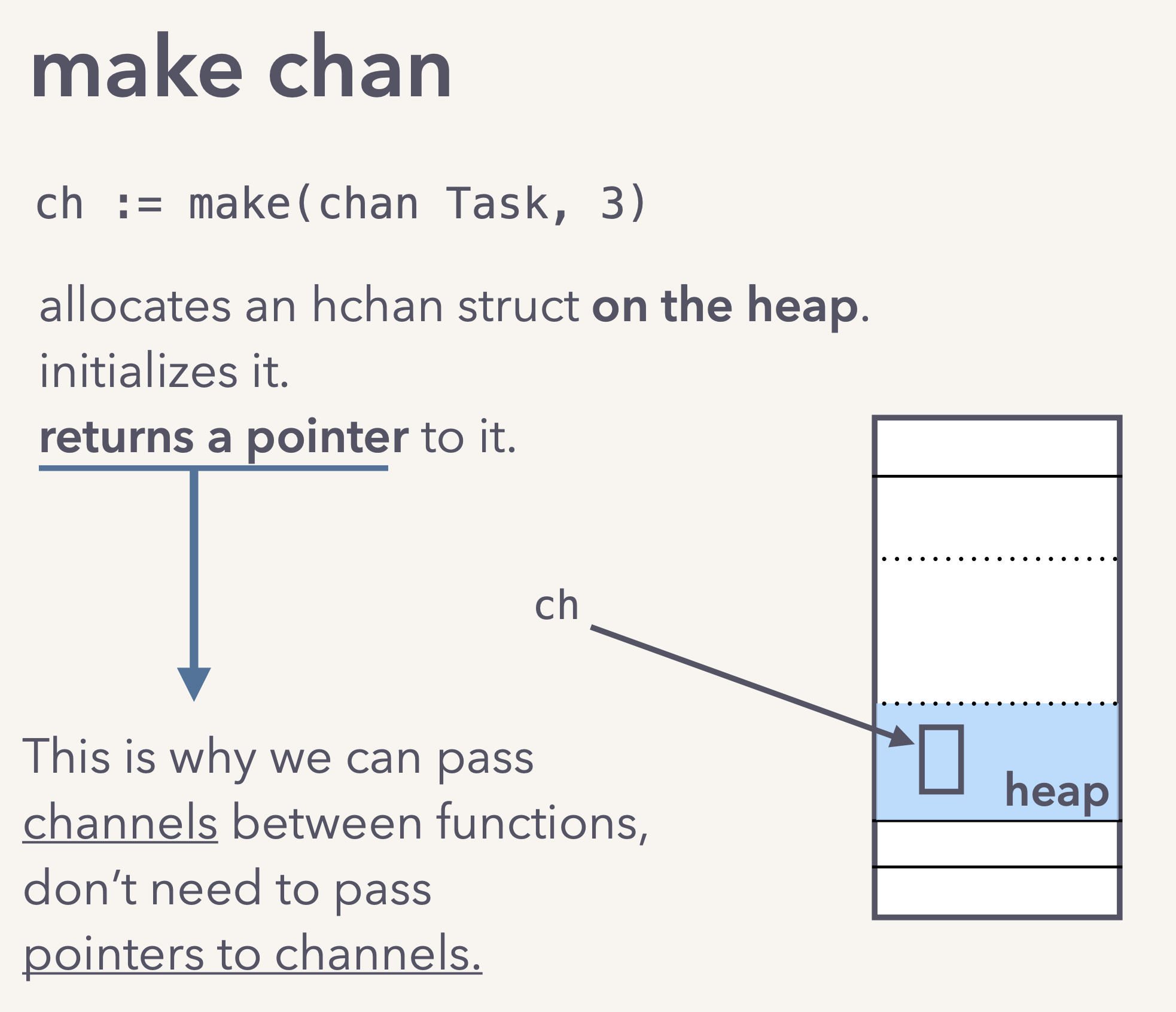
在调用make方法创建Channel的过程中,会在堆中创建实例对象并返回指针:
Channel的特性
- 通过互斥锁mutex实现goroutine-safe,多个 goroutine 可以同时访问一个 channel,并且是协程安全的。
- 通过循环队列实现先入先出(FIFO)
- 可以用在不同的goroutine间传递数据,并且是通过仅共享hchan + 数据拷贝实现的。
- 可以导致 goroutine 的 block 和 unblock,channel的阻塞是通过goroutine自己挂起,唤醒goroutine是通过对方goroutine唤醒实现的。
- 发送goroutine是可以访问接收goroutine的内存空间的,接收goroutine也是可以直接访问发送goroutine的内存空间。
- 无缓冲的channel始终都是直接访问对方goroutine内存的方式,把手伸到别人的内存,把数据放到接收变量的内存,或者从发送goroutine的内存拷贝到自己内存。省掉了对方再加锁获取数据的过程
- 接收goroutine当channel关闭时,读channel会得到0值,并不是channel保存了0值,而是它发现channel关闭了,把接收数据的变量的值设置为0值。
使用Channel Demo
1 | |
源码分析实现原理
TODO
Goroutine
GMP模型
在Go的并发编程模型中,不受操作系统内核管理的独立控制流不叫用户线程或线程,而称为Goroutine。Goroutine通常被认为是协程的Go实现,实际上Goroutine并不是传统意义上的协程,传统的协程库属于用户级线程模型,而Goroutine结合Go调度器的底层实现上属于两级线程模型:
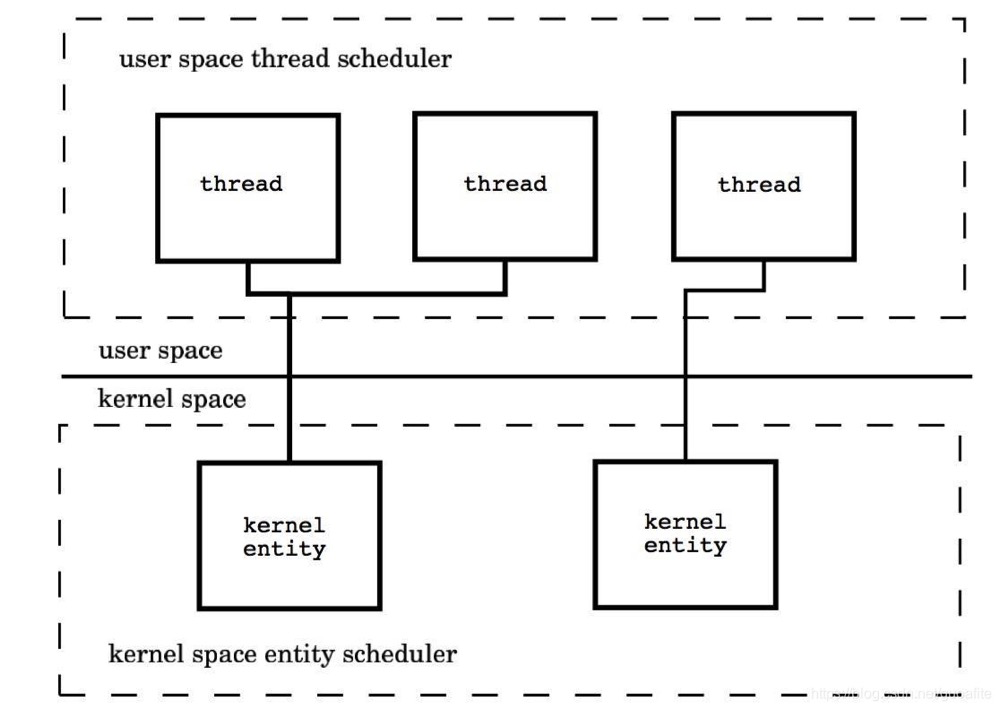
用户线程与KSE是多对多关系(M:N),两级线程模型既不是用户级线程模型那种完全靠自己调度的也不是内核级线程模型完全靠操作系统调度的,而是一种自身调度与系统调度协同工作的中间态,即用户调度器实现用户线程到KSE的调度,内核调度器实现KSE到CPU上的调度。
Go搭建了一个特有的两级线程模型。由Go调度器实现Goroutine到KSE的调度,由内核调度器实现KSE到CPU上的调度。Go的调度器使用G、M、P三个结构体来实现Goroutine的调度,也称之为GMP模型
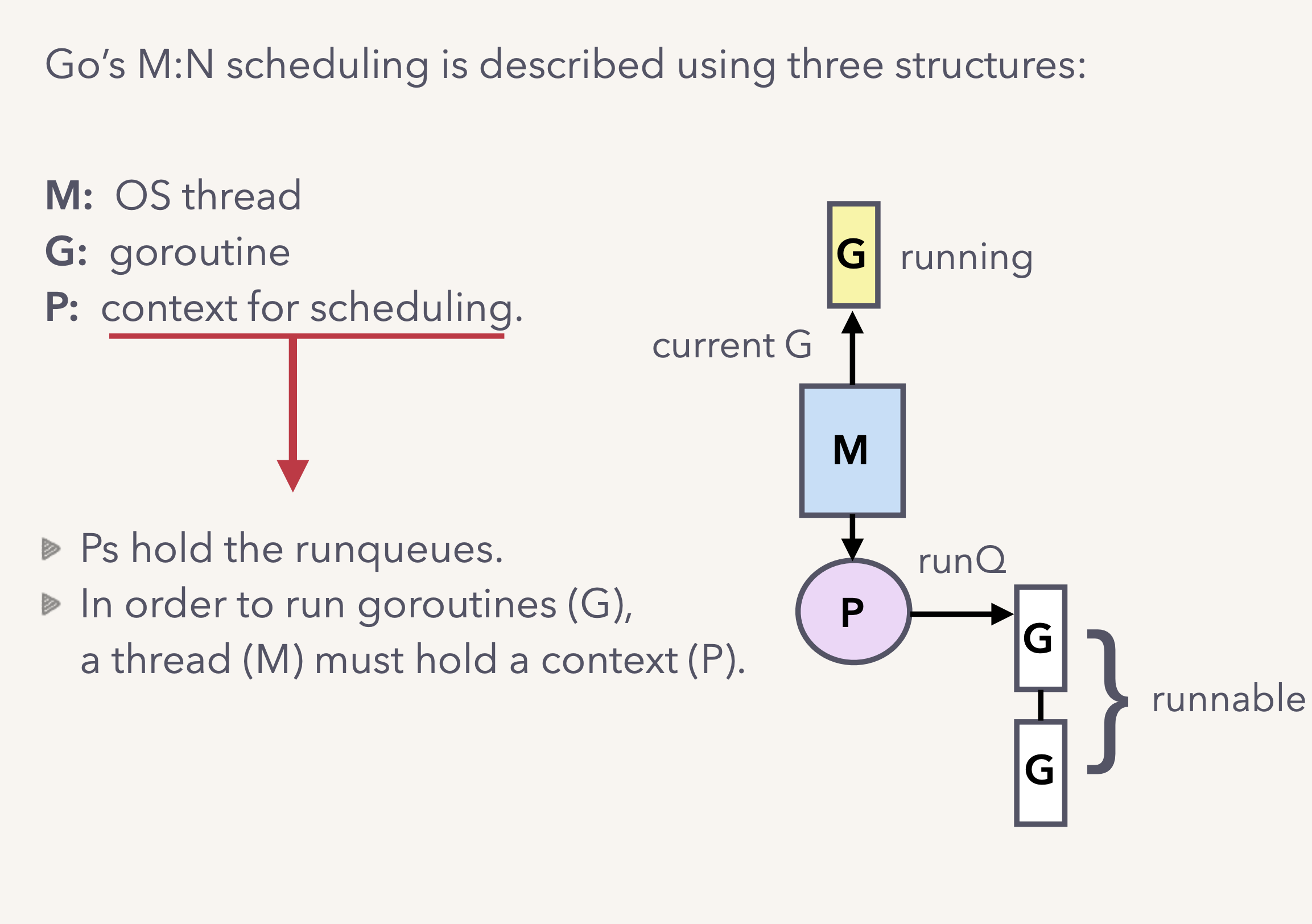
其中GMP都是runtime包下的结构体,分别用来抽象不同的实体:
- M代表操作系统线程,代表着真正执行计算的资源,由操作系统的调度器调度和管理。M结构体对象除了记录着工作线程的诸如栈的起止位置、当前正在执行的Goroutine以及是否空闲等等状态信息之外,还通过指针维持着与P结构体的实例对象之间的绑定关系
- G代表goroutine,G存储Goroutine的运行堆栈、状态以及任务函数,可重用。当Goroutine被调离CPU时,调度器代码负责把CPU寄存器的值保存在G对象的成员变量之中,当Goroutine被调度起来运行时,调度器代码又负责把G对象的成员变量所保存的寄存器的值恢复到CPU的寄存器
- P代表调度上下文,对G来说,P相当于CPU核,G只有绑定到P(在P的local runq中)才能被调度。对M来说,P提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等。它维护一个局部Goroutine可运行G队列,工作线程优先使用自己的局部运行队列,只有必要时才会去访问全局运行队列,这可以大大减少锁冲突,提高工作线程的并发性,并且可以良好的运用程序的局部性原理
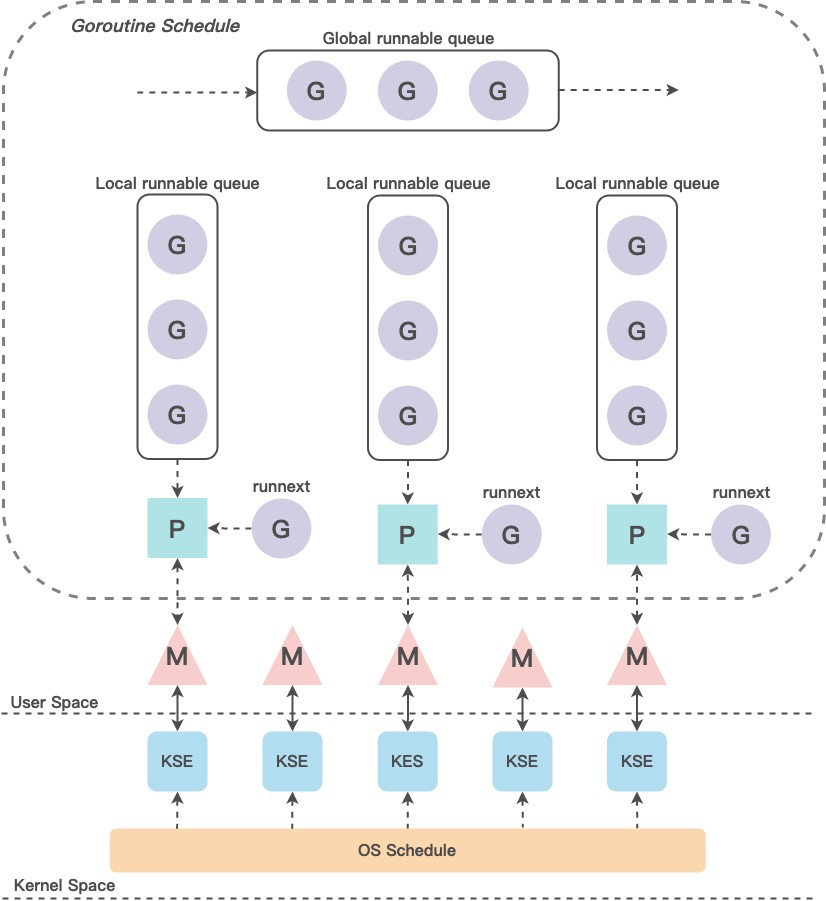
源码分析实现原理
TODO
一个Demo
1 | |
P的个数是通过runtime.GOMAXPROCS设定(最大256),Go1.5版本之后默认为CPU逻辑核心数。 在并发量大的时候会增加一些P和M,但不会太多,切换太频繁的话得不偿失。
一般将P设置为CPU的逻辑线程数,可以最大化多核CPU的性能,同时减少内核级线程切换的开销
1 | |
单从线程调度讲,像Java、C++等其他语言的多线程都是OS线程的抽象,是由OS内核来调度的。相比大多数并行设计模型,Go比较优势的设计就是P上下文这个概念的出现,如果只有G和M的对应关系,那么当G阻塞在IO上的时候,M是没有实际在工作的,这样造成了资源的浪费,没有了P,那么所有G的列表都放在全局,这样导致临界区太大,对多核调度造成极大影响。而Go语言的goroutine则是由Go的运行时(runtime)自己的调度器Saga调度的,这个调度器复用/调度m个goroutine到n个OS线程。 其一大特点是goroutine的调度是在用户态下完成的, 不涉及内核态与用户态之间的频繁切换,包括内存的分配与释放,都是在用户态维护着一块大的内存池, 不直接调用系统的malloc函数(除非内存池需要改变),成本比调度OS线程低很多。 另一方面充分利用了多核的硬件资源,近似的把若干goroutine均分在物理线程上, 再加上本身goroutine的超轻量,以上种种保证了go调度方面的性能。
Saga scheduler
TODO
参考
https://www.youtube.com/watch?v=KBZlN0izeiY
https://speakerdeck.com/kavya719/understanding-channels
https://www.jianshu.com/p/afe41fe1f672#comments